
前脚Open AI发布了超越业内的文生视频模型Sora,后脚谷歌另辟蹊径发布了交互式世界生成模型Genie。面对各家人工智能大模型的激烈角逐,小编和大家一样发出深深的感叹:我们当真是处于一个高速演进的AI时代,仿佛一不留神,大模型领域就会有一个大事件发生。
Genie的发布,引起了人们对谷歌在人工智能领域地位的讨论。有人认为“似乎谷歌正在回归领导人工智能。”
要知道在人工智能大模型兴起初期,谷歌这位AI行业大佬迟迟未加入大模型的研发队伍,面对Open AI这样强大的竞争对手,谷歌已经落后一大截。在语言大模型赛道上,谷歌先后发布了语言模型Gemini和Gemma,但是发布的模型完整度不够,相对Open AI ChatGPT刷屏式的好评,谷歌终于不得不承认自己在AI领域已经是“廉颇老矣”。
但此次,谷歌另辟蹊径,发布的这款交互式世界生成模型Genie,引起了业内很高的关注度。业内人士对于谷歌在AI领域的发展期待又有所回升。
据悉,Genie大模型主要由三部分构成,一个简单且可扩展的潜在动作模型、一个视频分词器和一个离散标志生成器。潜在动作模型负责推断每对帧之间的潜在动作,视频分词器将原始视频帧转换为离散标志(token),而离散标志生成器则将这些标志转换为生成环境所需的潜在表示。
Genie模型最大的亮点在于其能够通过单个图像提示生成交互式、动作可控的2D环境。这一特点使得Genie所生成的视频内容,在游戏开发、虚拟现实领域中具有很高的应用价值。
想象一下,你正在设计一个游戏场景,你需要一个特定的环境、角色和互动元素。使用Genie模型,你可以通过手绘草图或AI生成的图片,快速生成一个符合你需求的2D世界,很大程度上提升游戏开发的效率。


Genie根据图片生成动作可控的2D世界
尽管Genie突破了常规的视频生成大模型,只需要一张图片就可以创建一个可操控的2D世界,但Genie依然存在一些缺点。
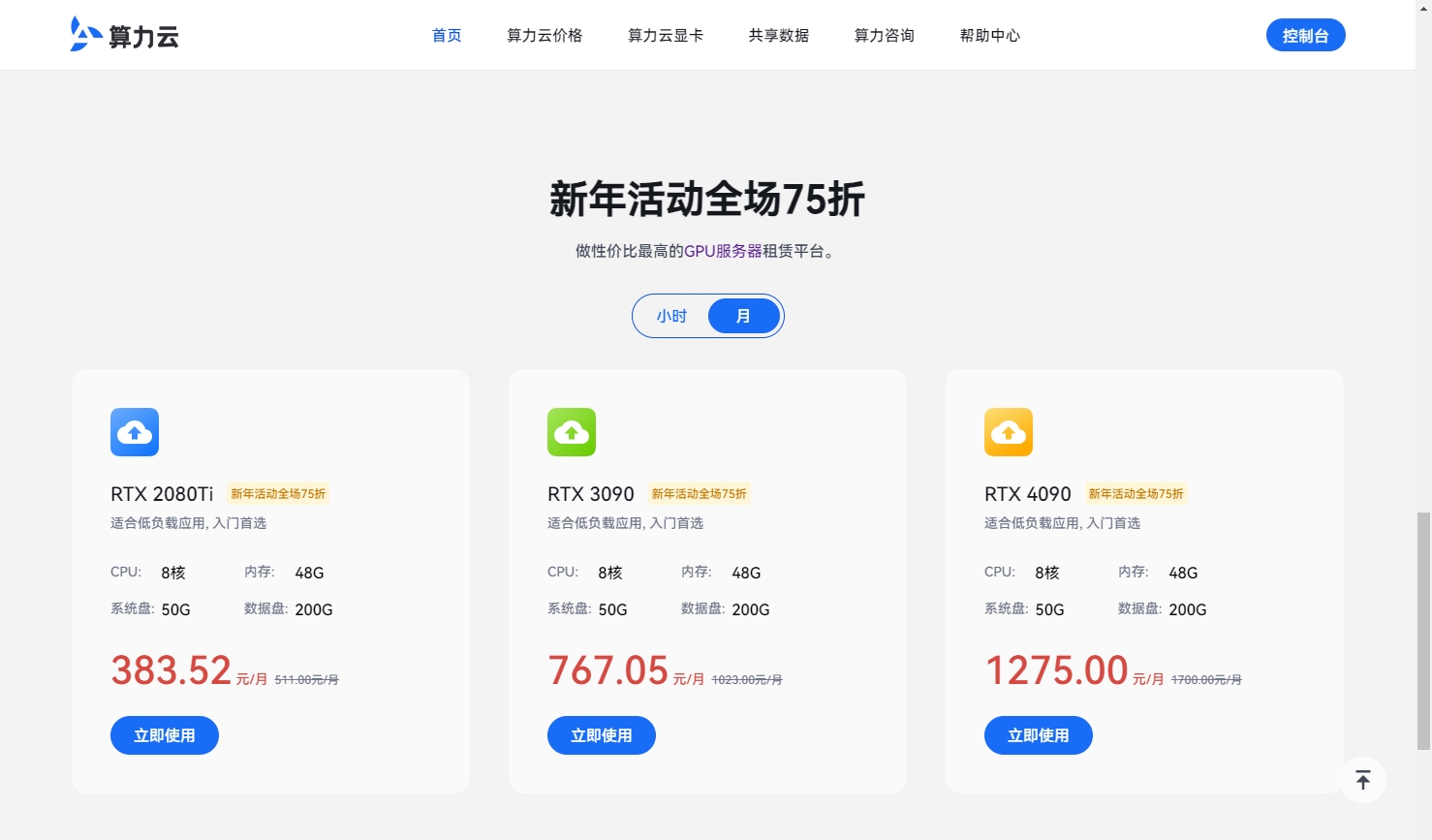
比如Genie通过图像生成动作可控的游戏世界的过程中,对计算资源的需求较高,可能导致在计算资源有限的环境中难以运行。但好在目前有很多算力租赁平台可以为用户提供所需的计算资源,以便更好地训练和运行Genie模型。
例如在算力云平台租用高性能的GPU,用户就可以更灵活地应对计算需求,保证模型正常训练和运行,提高模型运行效率,同时避免购买GPU的高额成本,做到随取随用。
另外Genie的训练视频是160 x 90像素的超低分辨率视频,每秒只有10帧,它生成的“游戏”同样是低分辨率的,每秒只有1帧。因此与先前Open AI推出的Sora模型相比,Genie在画质清晰度方面存在差距,生成的“游戏”距离实际可玩还很远。

Genie根据小朋友的手绘图生成的视频
但好在Genie并不是最终产品,相信在谷歌不断优化模型,其他AI创业公司也在不断更新模型,不久的将来,技术成熟的交互式虚拟世界生成模型将出现。
今天的AI资讯分享到此结束啦,欢迎伙伴们在评论区参与互动!





